Abstract
Biological problems are usually complex due to their multi-parametric nature and to the fact that these parameters are often interdependent. However, the available methodologies for the optimisation of biological processes are usually impractical, since they generate an explosion in the number of experiments to be performed, and also difficult to perform, since they lack easy‐to‐use software. The latter restricts their practice to specialist users who are experienced in handling complex algorithms. To address both these problems, we have constructed a simple‐to‐use and freely available graphical user interface to empower a broad range of experimental biologists to employ evolutionary algorithms to optimise their experimental designs. The platform first adopts a Genetic Algorithm to scan a wide range of possibilities, thus ensuring that the search leads to the discovery of the subspace where the optimal combination of parameters resides. Symbolic Regression is then employed to construct a model to evaluate the sensitivity of the experiment to each parameter under investigation. We believe this tool to be an attractive alternative to commercially available software for both academic users and for experimental users in SMEs whose limited funds do not allow them to employ dedicated statisticians to carry out such tasks or to purchase commercial software.
Outcomes
The first task of the project involved demonstrating the applicability of the proposed approach and the second involved developing the software tool.
The applicability of our hybrid approach was demonstrated by optimising cultivation conditions for recombinant protein production by an inducible strain of the yeast Pichia pastoris (Komagataella phaffii). For the set-up under investigation, where the expression of a model protein (Human Lysozyme) was investigated under an inducible alcohol oxidase (AOX) promoter in a microbial host, the objectives were determined as: (1) the maximisation of cell growth until the induction of protein production, in order to facilitate the optimal use of resources to make as much of the cell population available for protein production as possible in the post-induction stage; (2) the maximisation of the overall protein activity at the end of the induction period; (3) the minimisation of cell growth during the period of induction in order to allow the resources to be preferably used by protein production rather than growth, and (4) the maximisation of productivity (protein activity/cell) in order to achieve the environmental configuration that allowed the cells to operate in the most efficient way. These objectives were assigned equal weights as there was evidence in the literature to suggest the dominance of one or more of these objectives over the others within this context.
The next stage in the process was the selection of the parameters that were considered to contribute substantially to these objectives. The preliminary experiments detailed above highlighted the importance of maintaining pH at a fixed value as an environmental effector (in the range of 3-7 using suitable citrate/phosphate buffer) and several medium components including ammonium and glycerol; the growth-related macronutrients, methanol and sorbitol; the induction-related macronutrients, as well as magnesium, calcium, potassium, and iron, whose concentration values were reported to vary considerably in the literature. We investigated this 9-parameter system with each parameter defined at 32 different levels. The cultivation conditions were selected such that the tests could be conducted in defined medium using loose-cap tubes to prevent anaerobiosis; the experiments were run in triplicate.
A genetic algorithm, which was based on the evolutionary ideas of natural selection and genetics, was employed as the adaptive heuristic search algorithm to conduct the optimization study. The algorithm used a population of possible solutions to a problem to evaluate the feasible solution space and, over generations, successive populations would be fitter and therefore more adapted to their environment, as dictated by their objective function. The initial step of the algorithm was concerned with the generation of an initial population of solutions, which provided the randomly generated values for the environmental parameters within a specified range. The experiments were conducted for each of these populations in triplicate and the fitness of each population as defined by the objective function was determined. The fitness values were evaluated and the best-performing individuals were selected. The population values for the best-performing individuals were ‘mated’, random ‘mutations’ were introduced and a new generation of populations was created. The fitness was evaluated and the procedure was repeated until a satisfactory convergence was observed in the objectives, which were represented by the convergence of the productivity and the protein activity values.
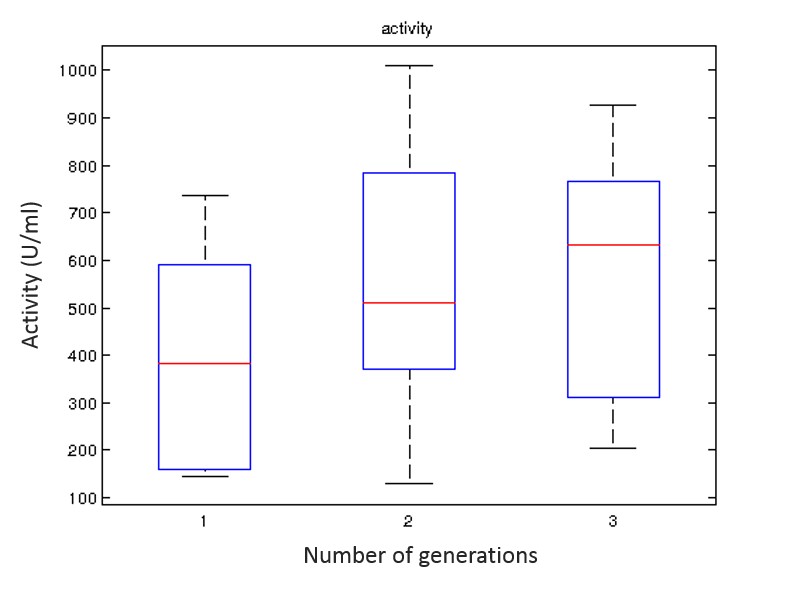
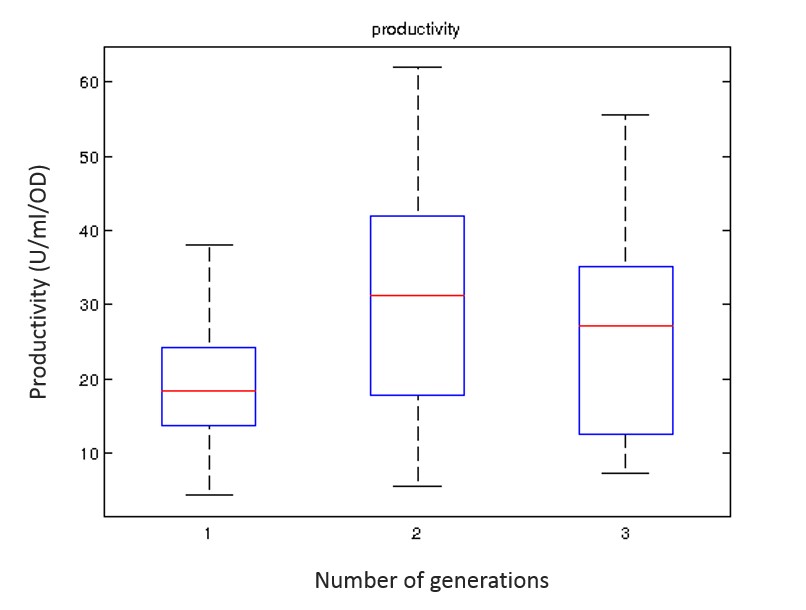
A convergence in the performance metrics was observed after conducting three generations of experiments for 150 individuals and therefore the iterative procedure was halted due to this convergence. The optimised medium composition was further investigated for fine-tuning and the elimination of problems regarding precipitation via population profiling. The performance of this optimised set of environmental conditions was then verified by benchmarking its performance against other conditions reported in the literature. The new set of conditions was shown to yield a more than 80% improvement in Human Lysozyme activity and an over 55% improvement in productivity on average over the generations. The new recipe was shown to perform better to boost productivity and r-protein activity than any other medium reported for K. phaffii.
Having determined the optimal solution in that sub-space, we constructed a regression-based model to describe the interdependencies among the input parameters, which affect the output parameters and to investigate the sensitivity of the objectives to the input parameters. Multiple linear regression (MLR) models, commonly employed in Design of Experiments failed to describe our search space acceptably since a large number of factors and their interactions contributed to the construction of this search space under investigation. So, as the number of factors under investigation increased, more complex models were required to represent the possible interactions among those factors and to explain the variability in the output. Although non-linear models could provide a useful alternative in such instances, our lack of knowledge of the model structure opened up an infeasibly large number of possibilities to be tested. This led us to explore Symbolic Regression (SR) as an alternative approach to handle high-dimensional modelling problems with an unknown model structure. SR proved to be a powerful tool since it did not require any a priori knowledge of the model structure or the provision of such information to the algorithm ab initio. We then constructed models to describe our four different objectives: final cell density during the growth-promoting phase, further growth during the protein production phase, enzyme activity, and specific productivity. These models allowed us to explain the variation in each individual objective by the 9 factors under investigation. The residual sum of squares (R2) was selected as the metric to represent the proportion of variance in the models. The performance of these models in representing the variance in the dataset was compared to that of the MLR models. SR outperformed MLR in explaining the variance of the dependent variables, i.e. the individual objectives. The SR models could explains the variation in the cell growth until the induction of protein production, cell growth during the period of induction, overall protein activity and the productivity by 64, 75, 80 and 88 %, whereas for MLR models, these values were 12, 33, 60 and 61 %, respectively.
Having constructed the models, we conducted sensitivity analyses employing those batches of models to determine how sensitive each individual objective was to a small variation in each factor. We shifted the value of each factor from its determined optimum by 10% and investigated whether a similar response of 10% or higher was observed in individual objectives in their respective model pools, denoting such factors as major contributors. The sensitivity analysis revealed the distinction between what we call “operation-related” factors and “cell culture-related” factors in the experimental design, although the process of model construction was blind to the nature of the factors under investigation. We identified all dependent variables in the objective function to be highly sensitive to variations in the pH of the working culture. In this way, it was found to be imperative to have strict control over the pH of the cultivation during HuLy production by K. phaffii under the control of the alcohol oxidase promoter.
This task provided us with an optimised set of cultivation conditions and a novel choice of model-building strategy along with a descriptive model for the selected case study. We used the results of this first task in developing the Graphical User Interface (GUI) for the tool, which constitutes the second proposed task. CamOptimus is a tool for applying Genetic Algorithm (GA) to solve multi-parametric optimisation problems and Symbolic Regression (SR) to obtain models using the data generated during optimisation procedure to investigate the effect of individual parameters on the system of interest. The source code for the compiled software and the Graphical User Interface (GUI) of the application are available under free licensing (GNU General Public License) and they are submitted to the Open Data Repository at the University of Cambridge (www…) along with the User Manual of the GUI. The permanent link to the software has also been shared on the Cambridge Systems Biology Website (www.) to increase the visibility of the tool. The MATLAB Runtime environment (version 9.0.1) is needed to run the executable versions (the compiled version and the GUI) on computers with Windows OS or Mac OSX. The MATLAB Runtime is available under free licensing at http://uk.mathworks.com/products/compiler/mcr/.
The user first selects the action to be taken in the main page of the GUI; using Genetic Algorithm to solve a multi-parametric optimisation problem, or conducting Symbolic Regression analysis to investigate a given solution sub-space. Each action is comprised of successive steps and the decisions made in each step feeds into the next one, guiding the user through the course of action to be taken. The Genetic Algorithm interactive interface allows actions to be taken in a given order so as to guide the user through the steps of the procedure. It is comprised of two blocks of information; one for setting up the experiment and another for evaluating the results. There is a set of information required to be determined and fixed constant throughout the application and therefore, this should be set up as the initial step. The information the experimenter is asked to provide are regarding the objective(s) of the experiment and the factors of interest, which are thought to have an impact on the objective(s). There are several GA-associated parameters, which the user might wish to alter, and the interface allows these changes under the “Advanced settings”.
The first decision to be made in an optimisation experiment is to define the measurable objective(s) that need to be optimised. If there is more than one objective, the first question that the user needs to address is whether these objectives are equally important, and hence whether or not they can be assigned equal weights. The user also has to provide a name for each objective and select whether that target objective should be maximised or minimised. Combinations of objectives where some are minimised whilst others are maximised are allowed. As soon as any objective function is defined, modifications are then allowed in the next section, which asks the user to identify all factors that need to be optimised to achieve the described combined objective function.
The experiments to be conducted will be generated as a report of this initial setup. The user may wish to include additional parameters, which will not be optimised in the procedure but will be kept at a fixed value, just to have them appear on the generated reports for convenience. Such an example would be that the user may wish to optimise only a given fraction of the medium components whereas, in the lab, all components need to be included in the actual experiments. Including these unchanged parameters in the factors list will allow a full medium recipe to be generated automatically to facilitate lab work. The interface will allow additional factors to be included. For each individual factor, the user has to select whether this new factor will be a factor to be optimised or will just be monitored. For factors that will be optimised, a range in which values will be allowed to vary should be defined. For those factors that will only be monitored, a single value and a corresponding unit should be introduced.
Genetic Algorithm is a search heuristic that can be successfully applied to many problems. Therefore the parameters intrinsic to its mode of operation may need to be adjusted, might need to be adjusted, perhaps based on similar type of problems to which it has previously been successfully applied. Therefore, the user is allowed to make a selection either to accept the default parameters or to provide values for the mutation rate, the crossover rate, the number of bits and the selection probability. At this point, the user is ready to generate the first set of experiments in the optimisation procedure. Once these steps outlined above are designed and the experimental procedure has been initiated, they cannot be changed or modified in any way. The interface also ensures this. The file that the generated experiments are saved is designed in such a way that the user can take the printout to the lab to carry out the experiments. The measurable outputs for the objectives under investigation (initially generated as zeroes, later to be modified by the user) will also be recorded in the same worksheet. In case the experiments are carried out in replicates, the mean or the median values (as seen fit by the user) should be recorded in the spreadsheet. Once the experiments are carried out and the objective outcomes are recorded in the worksheet, the user is then ready to use the tool for evaluating their results and generating the next set of experiments if they see necessary.
The initial setup and the experiments files are uploaded for accessing the software for the upcoming generations The individual non-normalised scores for each objective, which can be used as an indicator of the improvement of the system over time, as well as an absolute frequency plot displaying (i) the distribution of values employed by a given factor over the generations, and (ii) the distribution of values employed in the best performing fraction of the most recent generation are plotted by the software Using these plots, the user then makes a decision on whether if they would like to proceed with a next generation of experiments, based on how satisfactory the convergence of the factors and the scores were. Once the optimisation procedure is terminated as a result of convergence, the user is then ready to take their results to the next stage to investigate their solution space by selecting Symbolic Regression in the main page. As in Genetic Algorithm section, the interactive interface allows actions to be taken in a given order so as to guide the user through the steps of the procedure.
The regression analysis is designed to follow the optimisation protocol employed in Genetic Algorithm section, and therefore the structure is designed to make use of the data generated in the earlier stages. However, the tool will accept any other spreadsheet, which was prepared in a similar format to that generated by the Genetic Algorithm Section of the Tool. The first column of the spreadsheet is recognised as the identifier column for the experiments, and by selecting the number of columns dedicated to the factors under investigation, the user classifies the columns into the factors and the objectives, which then appear in their cognate boxes. The user then selects which parameter(s) would be employed in describing which objective by the constructed model.
Once the model parameters and the objective to be modelled are determined, the user then has to decide on the purpose of the model to be constructed. The tool is suitable for constructing both descriptive models and predictive models. The exploratory model option employs as much of the experimental data made available as possible to describe the solution space and through evolutionary approaches, attempts to reach an optimal model structure as well as regression coefficients in order to best fit a function to the available data. The goodness-of-fit of the model is described by how well the model fits the experimental data. The predictive model option retains a pre-defined percentage of the complete dataset as the validation dataset in a completely randomised manner and employs the remaining fraction (the training dataset) for constructing the model with the best fit available. This time, the goodness-of-fit of the model is described by how well the model constructed using the training dataset fits the validation dataset and this is an indicator of its predictive success, by definition.
Following the selection of the type of model to be constructed, the advanced settings for the symbolic regression can be adjusted by prompting the user to accept or change the default settings provided in the software. Although some suggested default values for the population size, number of generations, maximum number of genes and the maximum depth are provided in the tool itself, we urge the user to change these default settings in order to construct models with improved goodness-of-fit. Increasing population size and the number of generations improves the model fitness, whereas increasing the maximum number of genes and the maximum depth increases the complexity of the constructed model, and may also contribute to the fitness of the model.
It is worthwhile to note that the parameter values provided here should be considered as independent of those discussed in the Genetic Algorithm Section. The concepts and the parameters employed in describing these concepts are similar for genetic algorithms and other approaches including but not limited to symbolic regression, which employs genetic programming, and therefore should be evaluated within their own context.
Once the settings are determined, the tool is then ready to construct the model. Depending on the parameters selected, the program may take a while to run and once the model is constructed, the user has the best-fitting model for running further sensitivity analysis as well as the model prediction and actual data plots for each data point and the scatter plots – prediction vs actual data for the training and the test sets along with the room mean squared (RMS) error and the regression coefficient (R2) values for each set. The significance of each factor (gene) is also provided.
The outcome was accomplished as planned in the Proposal.
Follow Up Plans
We would like to claim the additional £1000 for two main purposes; (a) full training and Q&A session for the use of the CamOptimus GUI aimed for all potential users – as proposed initially, and (b) completing the study based on the suggestions and the feedback we have received during the dissemination events. One major concern raised regarding the methodology was that only one test case was conducted to validate the approach. Due to the time limitations of the project, a comprehensive extension of the experimental validation could not be facilitated but an additional 6-months’ time would be sufficient to extend the work to a different experimental setup. Another concern was regarding the benchmarking. Since the area of application is industrial biotechnology, a scale-up study and performance comparison was suggested by the audience. Therefore, we would like to focus on these 3 major aspects during the follow-up. The training and Q&A sessions will be held for researchers working in SMEs and other industrial collaborators, who are interested in the tool and for academic researchers separately. Scale-up experiments for further benchmarking will be carried out within the first month of the follow-on period. The remaining 5 months will be allocated to conducting an optimisation study, again with biotechnological significance. The system under investigation will be a continuous cultivation system, which has huge challenges with respect to its optimisation, both in academia and in industry, which employ both mammalian cultivations and microbial fermentations. The first 3 months of the allocated period will be spent on optimisation of growth environment and the remaining 2 months will be spent on employing the optimised setup on real systems and adapting the scalable characteristics from batch cultures mimicking continuous systems (during exponential phase of growth) to real continuous setups running in fully controlled mode. This will also allow the investigation of the flexibility of the approach by extending its limits.
Progress
The experimental task of the project was completed within the first 3 months and the optimised set of conditions was benchmarked against previously reported conditions during the 4th month as initially proposed. During the first three months of the project, we carried initial discussions with Dr John Kendall from ZuvaSyntha Ltd, to understand industrial perspective on the Design of Experiments and the typical use of commercially available DoE software (such as Jamp®) in solving multi-parametric optimisation problems. With these concerns and suggestions in mind, the first draft of the GUI for the tool, which consisted only of the Genetic Algorithm Section was made available. We had a chance to present the idea to the academic audience as a poster in a large conference (Annual Conference of the Microbiology Society 2016) and as an invited talk in a small focused meeting on Synthetic Biology (3rd Meeting of Applied Synthetic Biology in Europe). Both meetings allowed us a chance to receive very useful feedback from academia as initially proposed. The Annual Conference of the Microbiology Society 2016 allowed us to meet members of the Kay lab (MRC Laboratory of Molecular Biology, UK), who agreed to become beta testers for the tool, which helped substantially during the development process. The networking during the 3rd Meeting of Applied Synthetic Biology in Europe resulted in an invitation to present CamOptimus in the 17th European Congress of Biotechnology (ECB) 2016 through a short talk. Since this was a meeting with more than 1000 registrants, it allowed us to reach a wide audience with broad areas of interest. The remaining three months of the project was focused on exploring different modelling schemes for the exploration of the solution space and the implementation of the most suitable approach into the GUI. The tool was finalised and a manuscript has been drafted for the results. A pre-submission enquiry has been made for PLoS Biology and the Editorial Board invited us for the submission of a full manuscript for a Methodology Article.
The progress of the project deviated from the initial Proposal based on the feedback we have received during the course of the Project. We had to reshuffle the way we allocated the budget accordingly. In the first task, where we verified and demonstrated the applicability of the methodology, the convergence towards the optimised set of conditions was achieved much earlier than initially expected, resulting in allocation of less resources (time and expenditure) towards the experimental work. However, we were invited to present our final work in ECB2016, before our proposed dissemination plan. The feedback we have received during the dissemination helped us to shape the follow-on work in a different way, as will shortly be discussed.
Outputs
Poster presentation: S16/P2 - CamOptimus: A self-contained, user friendly multi-parameter optimisation platform for non-specialist experimental biologists, Ayca Cankorur-Cetinkaya, Duygu Dikicioglu, Joao Dias, Jana Kludas, Juho Rousu, Stephen G. Oliver – Annual Conference of the Microbiology Society, 21–24 March 2016 (abstract book and poster attached – not available online) (https://www.engbio.cam.ac.uk/synbiofund/CamOptimus_project_folder/dissem...) – SynBio Fund acknowledged
Short talk: CamOptimus: A self‐contained, user‐friendly multi‐parameter optimisation platform for non‐specialist experimental biologists, Duygu Dikicioglu – 3rd Meeting of Applied Synthetic Biology in Europe, 22-24 February 2016 (http://www.efb-central.org/Synthetic/Documents/prg.pdf) – SynBio Fund acknowledged
Short talk: A roadmap to improve yield of the recombinant proteins production: a case study employing Komagataella phaffii as the host organism, Ayca Cankorur-Cetinkaya – 17th European Congress on Biotechnology, 3-6 July 2016 (http://ecb2016.com/wp-content/uploads/2016/07/FINAL-ECB-Programme-plus-Final-ECB-Programme-270616.pdf) – SynBio Fund acknowledged
Manuscript draft: Full title - A Tool for Exploiting Complex Adaptive Evolution to Optimise Protocols for Biological Experiments (invited for full submission to PLoS Biology), Ayca Cankorur-Cetinkaya, Joao Dias, Jana Kludas, Juho Rousu, Stephen G. Oliver, Duygu Dikicioglu (yet confidential) – SynBio Fund acknowledged
CamOptimus source codes, GUI for MS OS and MAC OSX, User Manual: http://dx.doi.org/10.17863/CAM.700
Demo for the CamOptimus GUI on action: (https://www.engbio.cam.ac.uk/synbiofund/CamOptimus_project_folder/camopt...) (attached)
Expenditure
1- Replacement of laboratory consumables from the SGO lab for the first task – consumable plasticware (aerated loose cap tubes, micropipette tips, microcentrifuge tubes (Eppendorf), Stericup Filter Units (Millipore), PVC spectrophotometer cuvettes, 96-well plates (Nunc)):
£229.02 (– from this Fund)
2- 1 x Portable computer
£1258.51
3- 2 x Attendance to 3rd Meeting of Applied Synthetic Biology in Europe
£1595.72
4- 1 x Attendance to the 17th European Congress on Biotechnology
£879.15
5- Travel and meeting expenses for industrial partner feedback on the development of the GUI of the software (meetings held at ZuvaSyntha Ltd., Welwyn Garden City)
£37.60